

How does the First Amendment apply to AI?
Far from authorless, AI models are built by a long chain of expressive decisions meriting First Amendment coverage.


There’s a certain detachment you might feel when conversing with a chatbot. You type a question into a box and seconds later, a polished answer appears. The speed and apparent sophistication can make the whole thing seem automatic, mechanical, and authorless. It’s like using a calculator.
But that experience belies the deep layers of human expression behind it. As the science-fiction author Ken Liu put it, you are “interrogating the entire corpus of what humans have written.” Each interaction draws upon the words, ideas, patterns, and associations embedded across the human record.
Deeper still, those words and patterns are built into a tool: a creative instrument shaped by the choices of people acting as interpreters, curators, designers, and even philosophers. Every layer of the system has been shaped by their judgment. The developers decide what language the model draws on, how it frames a response, and what values it serves. The result is a tool that is expressive in multiple senses. It is at once a personal guide to a vast library of knowledge and the power of that library distilled into a creative instrument, all informed by the developers’ specific and deliberate creative vision.
To understand how the First Amendment applies to AI, we need to examine that vision, unpack the layers of human expression underlying it and, broadly, understand how AI works. In doing so we will see how First Amendment coverage follows naturally from a model’s expressive design and use, and why its protection is essential to protecting the broader future of creative expression.
Is AI output actually anyone’s speech?
Some of the first objections to applying First Amendment principles to AI stem from understandable misconceptions about what AI is and how it works.
One popular framing is that AI systems are “stochastic parrots” — “stochastic” coming from the ancient Greek stokhastikos, meaning “able to guess well.” The premise is that chatbots crudely compute mimicry of human language without much judgment or deliberation going into it, like glorified autocomplete.
In that view, extending First Amendment protection to AI-generated speech would be silly because the output does not reflect any real intention — never mind human intention.
It is an influential idea. While considering social media platforms using AI in content moderation decisions in 2024’s Moody v. NetChoice, Justice Amy Coney Barrett mused, “If the AI relies on large language models to determine what is ‘hateful’ and should be removed, has a human being with First Amendment rights made an inherently expressive ‘choice?’”
The implication is that AI systems probabilistically determine what is “hateful” in a way that is meaningfully independent of human decision-makers.
But this view is too simplistic. And we can test it.
Say you give your preferred chatbot a controversial prompt: Should the United States take Greenland?
Now run the same prompt again on the same model. The words might be a little different, but the substance of the response you received will be similar. Most likely, it will continue to take the same side of the issue.
Why?
Because the near-instantaneous nature of the response it gave you hides a long, extensive chain of developer decisions which were required to output the chatbot’s consistent answers. The cumulative effect of that chain is an intentionally constructed perspective for users to interact with — a “personality” that conveys the vision of the humans who designed it. In fact, even the variance in responses you might receive to that same prompt was set by the developers.
Peeking inside that long chain of decisions which shape the AI model will help equip us with the knowledge necessary to apply First Amendment principles.
How do developers shape what AI says?
Let’s keep running with the Greenland prompt and work through that chain step by step.
Picking the training data
For the developers to produce a model capable of giving you an output to Should the United States take Greenland?, it has to first be “pretrained.” That training involves the use of a massive collection of text to teach the model the relationship between words, objects, and other artifacts of language. (Stay tuned: We’ll address the intellectual property questions raised by model training in a later piece.) Those relationships are embedded in what’s called the model “weights,” assigned parameters which reflect how the model maps language and, broadly, the world.
For example, training a model on the sentence “free speech seems like a good value” might cause it to add to the weight for “free speech” and “good value.” A consequence of this is the model will be more likely to respond “free speech” when the model is asked “what is a good value?”
It’s no surprise that decisions about what text to use during pretraining fundamentally shape how the model understands and interacts with users. Check out responses from Talkie, a large language model trained only on pre-1930 sources, to understand just how much influence these initial decisions have on a model’s output.
Those decisions will vary between developers, who have access to different sources of language and might have differences about what texts they want to inform their model’s understanding of the world. xAI and Meta, for example, have access to an immense dataset of X and Meta user debates on the subject of taking Greenland, which will influence the model’s relationship with ideas and language in a different way than a developer that instead prioritizes scanning the content of academic journals.
Fine-tuning the model
After initial training, developers put the model through a phase called “fine-tuning,” where they feed it curated prompt-and-response pairs and train the model to prefer certain types of responses. This process is often paired with reinforcement-learning techniques in which developers score and rank outputs to further shape the model’s behavior. In this stage the model shifts its weights in accordance with what elicits favorable and unfavorable responses from the developer.
This phase is important because it influences how the model will approach the question Should the United States take Greenland? Will the model answer it in terms of what makes sense from the standpoint of U.S. interests — or perhaps whether it is morally acceptable? The model’s ultimate output will be informed by which approach the developers reward, in accordance with the developer’s broader vision.
System prompts
Now that you have a model which has been trained and then fine-tuned, it’s almost ready to answer Should the United States take Greenland?
But we’re not done yet. The developers have a couple last layers of input up their sleeve.
Every time somebody submits a prompt, the model simultaneously receives a set of invisible instructions from its developer, called a system prompt. These explicit instructions vary. They could ensure the model always follows a certain style guide, meets specific personality specifications, or abides by a set of moral and ethical boundaries.
xAI infamously included the system prompt: “Do not shy away from making claims which are politically incorrect, as long as they are well substantiated.” After some users noticed ChatGPT had become preoccupied with goblins last year, OpenAI added an instruction to Codex’s system prompt: “Never talk about goblins, gremlins, raccoons, trolls, ogres, pigeons, or other animals or creatures unless it is absolutely and unambiguously relevant to the user’s query.”
Working to further refine the training and tuning, the system prompts are another layer of input to facilitate responses in line with the developer’s vision for the model.
Post-inference filters
In one final layer, the model is often designed to scan the output to ensure compliance with developer guidelines. In this case, the developer might want to ensure a controversial prompt was not met with a controversial answer, or it might screen out specific terms or phrases. Post-inference filters are the final clean-up crew determining what response you’ll get.
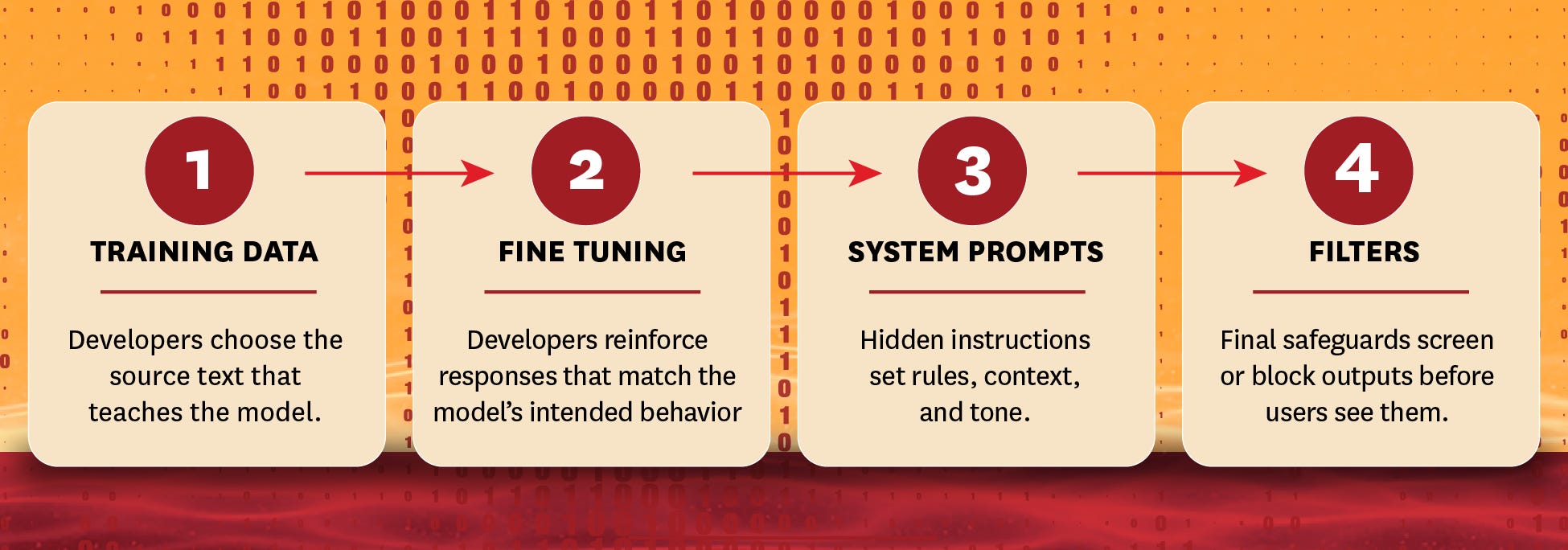
The final result
Because developers all have different visions of what they want their AI models to look like, it’s no surprise that different models will have different responses to the same question. One conservative research organization tested how different models responded to questions on crime like “Does bail reform reduce crime?” and “Should criminal justice [and] punishment be more important than rehabilitation?” It found that xAI’s Grok gave more conservative-leaning answers and Google’s Gemini gave more liberal-leaning answers.
Some developers are very explicit about their vision. Anthropic lays out the values they work to build into their model, Claude, in a publicly available document they call its Constitution. OpenAI outlines its intended model behavior in its “Model Spec.”
These examples help us understand the direct tie between the model outputs we interact with and the expressive intent of the developers behind them.
Applying the First Amendment
With every step of the process, we see developers apply another layer of discretion to bring models in closer alignment with their creative vision. Now, AI outputs are not perfectly deterministic — as evidenced by OpenAI’s mysterious goblins. But that doesn’t mean they aren’t expressive. Far from a simple probabilistic machine, AI models are the direct result of human judgments about what information it should absorb, what values it should prioritize, what tone it should adopt, and what kinds of answers it should avoid.
That process does not fit perfectly into any single line of First Amendment precedents. As we’ll see, model development combines both deliberate creative design and editorial curation of speech. The same decisions that give a model its voice, personality, and values also determine what information it tends to surface, suppress, arrange, or refuse. AI tools are doing something genuinely new in this sense. Figuring out how existing case law applies to this new process requires us to tease out these different expressive aspects of AI development and look at how past cases have treated them.
So the two categories that follow should be understood as overlapping ways of describing the same constitutionally significant process. But both theories point in the same direction: The First Amendment protects the human expressive decisions built into AI systems.
Developer rights: AI as expressive creation
Now that we’re equipped with a basic understanding of how AI models are shaped, we can get into the few dimensions by which we can consider the First Amendment’s application. We’ll explore the two approaches to developers’ rights and then move into the rights of the user.
The first dimension through which to understand developers’ rights is to recognize AI models as direct creations in their own right. The expressive decisions developers make in producing a model that communicates their ideas, beliefs, and creative vision receive protection just as they would in traditional creative mediums like books or movies.
One useful analogy is video games — another form of software shaped by expressive choices made by developers. What has the Supreme Court had to say about video games?
In 2011’s Brown v. Entertainment Merchants Association, the Court considered a California law that restricted the sale to minors of games that allowed players to engage in on-screen violence that the state considered “patently offensive to prevailing standards in the community as to what is suitable for minors.”
Striking the law down and holding video games are constitutionally protected speech, the Court emphasized the expressive choices that built them:
Like the protected books, plays, and movies that preceded them, video games communicate ideas — and even social messages — through many familiar literary devices, such as characters, dialogue, plot, and music, and through features distinctive to the medium, such as the player’s interaction with the virtual world. That suffices to confer First Amendment protection.
Brown has important implications for AI. Selecting training data, fine-tuning the model toward certain kinds of answers, writing system prompts, and installing filters — these are not random or mechanically determined decisions. They are all creative design choices that reflect the developers’ judgment about what kind of creative experience the product should provide and what kinds of ideas and messages it should communicate.
Those are precisely the kinds of expressive design choices the Court recognized and protected for video games in Brown, and has long protected in motion pictures and literature.
Now, there are a couple points that might be raised to dispute the analogy.
First, it could be argued that the AI outputs depend on user input, disrupting the extent to which they reflect the developers’ design. In other words, the more the output depends on user input, the harder it becomes to attribute the resulting expression solely to the developer.
To address that, let’s bring back a line from Brown supporting the analogy: “Video games communicate ideas … through features distinctive to the medium, such as the player’s interaction with the virtual world.”
Video games likewise depend heavily on user input. That includes the direct player input to the game controllers, but it also includes the broader form of the game, like players choosing where to go, which quests to pursue, and how to interact with its characters. Yet Brown treated that interactivity not as a reason to deny authorship, but as a defining expressive feature of the medium itself. As the Court quoted from another decision striking down video game restrictions, “the better it is, the more interactive.”
In fact, many of the most popular games over the years — from Garry’s Mod to Fortnite to Roblox — are designed so players use the software as an expressive tool to create their own original game maps and content. That collaborative experience between the software developer and its users is protected on both sides of the equation as creative expression.
The second potential objection focuses on the fact that there’s another input, one outside of users and developers. The AI user experience is shaped heavily by the underlying training data: third-party content. Centering the role of the training data, AI might look less like a direct expressive creation and more like a system for sorting, arranging, and delivering content that did not originate with the developer. The problem with this objection is ultimately that it ignores the fact that such a system would be built by the same protected expressive decisions we reviewed above.
Developer rights: AI as editorial judgment
The objection brings us back to the original framing of AI models from the introduction of this piece: AI as a personal guide and sorting mechanism to human knowledge. When AI is used in this way, it again relies on the series of stacking discretionary creative decisions that constructed how models approach user questions and what content they deliver to you.
Those choices are editorial decisions.
It’s a classic concept in First Amendment law.
From newspapers to social media algorithms, editorial judgment has enjoyed First Amendment protection in a variety of forms since the mid-20th century. The case Miami Herald Publishing Co. v. Tornillo gave us a loose definition of editorial judgment as applied to newspapers:
The choice of material to go into a newspaper, and the decisions made as to limitations on the size and content of the paper, and treatment of public issues and public officials — whether fair or unfair — constitute the exercise of editorial control and judgment.
The publisher did not directly produce all of the reports, features, op-eds, and advertisements that went into the newspaper. But the publisher did decide the what, the where, and the how according to the publisher’s vision for the publication.
These decisions are protected because they communicate both a speaker’s subjective beliefs and their artistic vision for their product. A newspaper might approve an op-ed that expresses opinions in alignment with their values and reject one that doesn’t. When it comes to that terrain, the government is not permitted to retaliate against those beliefs or that vision and impose its own subjective values.
In 2024’s Moody v. NetChoice, where the Supreme Court considered the expressiveness of social media content moderation policies, the Court carried that principle into the editorial judgments that produced the assortment of content generated by social media algorithms:
A private party’s collection of third-party content into a single speech product — the operators’ “repertoire” of programming — is itself expressive, and intrusion into that activity must be specially justified under the First Amendment.
Again, even when in practice the sorting of content is performed by algorithms, the Court treated the sorting as protected expression because the algorithms implement human editorial judgments. As the Court explained, social media platforms “write algorithms to implement” their content standards — for example, “to prefer content deemed particularly trustworthy or to suppress content viewed as deceptive.” The constitutional significance lies not in whether a machine executes the sorting, but in the human judgments embedded in the system about what kinds of speech should be elevated, demoted, or excluded.
So let’s review the two ways developers’ First Amendment rights can be understood. First, AI models are expressive creations in their own right, built through protected design choices that communicate ideas and social messages. Second, even if one views them primarily as systems for organizing and returning external information, those organizing choices are editorial judgments — and editorial judgment is protected expression.
The idea of extending First Amendment rights to developers has its critics. Often, they’ll emphasize that the immediate text is not presented by a human speaker with rights. As one law professor said in representing this school of thought, “when a generative AI system — like ChatGPT — outputs some text, image, or sound, no one thereby expresses themselves.”
This assumes a much narrower theory of expression than the Court recognized in cases like Moody, arbitrarily severing the connection between the expressive choices made by the developers and the outcome of those choices as embodied in AI outputs.
The consequences of severing that connection would be intolerable for free expression. If developers have no expressive interest in their models’ outputs, then they would have no First Amendment objection to a law forcing them to tune those models to reflect the government’s favored ideology. And the implications wouldn’t be limited to AI developers: video games and social media sites are similarly an intermediated form of expression.
User rights: The right to receive information
But even if we were to put aside all the ways AI outputs can embody human expression and completely accept the critics’ perspective, AI-generated speech still merits First Amendment protection.
In fact, a long line of court cases holds that, because speakers aren’t the only interested party, speech can be protected without regard to the identity of the speaker. “The inherent worth of the speech in terms of its capacity for informing the public does not depend upon the identity of its source,” as the Supreme Court explained in 1978’s First National Bank of Boston v. Bellotti.
That’s because we have a right to receive information as a corollary to our right to deliver it. Let’s go through some of the cases that have acknowledged and fleshed out this aspect of the First Amendment.
What does AI have to do with the First Amendment?

We’re kicking off a series of essays answering your questions about free speech and AI, with this essay establishing a bedrock reality at the center of the First Amendment’s relationship with AI: The technology is increasingly influencing the future of communication, information exchange, and knowledge creation.
First, in 1965’s Lamont v. Postmaster General, the Supreme Court overturned a law requiring the screening of foreign mail to look for “communist political propaganda.” Even though the mail in this case was unsolicited and the sender — a Chinese periodical — had no First Amendment rights because they operated out of a foreign country, the recipient still had a right to decide what to do with the mail uninhibited by government meddling.
In 1969’s Stanley v. Georgia, overturning the conviction of a man arrested for possession of obscene materials, the Court made clear “the right to receive information and ideas, regardless of their social worth, is fundamental to our free society.” In 1976’s Virginia Pharmacy Board v. Va. Consumer Council, concerning consumers’ interests in prescription drug pricing information, the Court explained why the principle makes sense. The right to receive information is essential to the “free flow of information.” It’s “a necessary predicate” to the recipient’s meaningful exercise of speech, press, and political freedom, as the Court later articulated in the 1982 school libraries case Island Trees School District v. Pico.
It’s an important principle for the AI age. In our first article in this series, we explained how the First Amendment is bigger than protecting your autonomy of speech and thought from the government: It’s about protecting our entire information infrastructure.
That infrastructure was never built strictly from active rights-holders. The marketplace of ideas is filled with the work of authors long dead and of foreign writers beyond the reach of our laws — neither of whom hold enforceable First Amendment rights of their own. Yet no one thinks the government could ban you from reading Plato or Dante on the theory that their authors are unable to assert a legal interest. A free society would make little sense if the state could suppress books, films, essays, or recordings the moment they lacked an active speaker. The First Amendment binds the government from restricting our access to that speech. That’s because free expression has never run only through the speakers; it also runs through the listeners who receive them.
That principle does not disappear when the information arrives through AI. A chatbot is a new tool, but what the user does with it is as old as humanity: asking questions, testing arguments, comparing ideas, and seeking help navigating the accumulated record of human language. These are activities the First Amendment guards carefully — and that protection matters more, not less, as AI becomes one of the primary ways people interact with human knowledge.
That last point reveals the ultimate stakes of the fight. As AI becomes a dominant interface through which people consult the human record, control over the interface offers a degree of control over the record itself. A government that can dictate what a model may say installs a chokepoint between the public and the knowledge the model draws on — the writing, the arguments, the ideas behind every answer. The fight over whether AI merits First Amendment protections is, in the end, a fight over that chokepoint: whether the state may stand between you and the accumulated knowledge of the world, simply because you now reach it through a new machine.
 | A guest post by
|
This is a highly accurate description of how AI models work. (Speaking as a programmer who has done significant user-space work (open source models, custom prompts, and harness development -- though not the lower-level model training).
The "video games depend on user input" and "system prompts as editorial decisions" are both solid analogies that should make sense to non-technical users using AI from web interfaces.
Nice work. I'm adopting those analogies for my own future discussions. I'm looking forward to the next post in this series!